
Deep Learning Team : Dunkin
주어진 음성 데이터에 대해서 알맞은 입술의 움직임을 만들어내는 립싱크 기술은 딥러닝 분야에서 가장 각광받는 분야 중 하나입니다. 영화를 예로 들어볼까요? 국적이 다른 배우가 개봉되는 국가의 언어에 맞추어 더빙한다면 어떨까요? 마치 같은 나라의 사람이 한국어를 배워 이야기 하는 것 처럼 청자에게 전달이 잘 될것이며, 몰입도 훨씬 잘 될 것입니다. 이 뿐만 아니라 다른 나라 정치인이 딥러닝 기술을 통해 한국어로 연설하여 의사를 전달하는 장면이 뉴스에 나오는 것도 놀랄 일은 아니지요. 따라서 자연스럽고 정확한 립싱크 기술은 미래의 서비스 산업에 큰 도약을 가져다 줄 것으로 기대됩니다.

그렇다면 립싱크는 어떻게 구현될까요? 크게 두가지 단계로 설명할 수 있습니다. 먼저 인공지능이 소리의 싱크에 맞는 입모양에 대한 주요 좌표를 잘 맞추도록 학습합니다. 그리고 나서 주어진 여러가지 점들의 집합을 기반으로 현실감 넘치는 사람의 얼굴을 합성할 수 있도록 학습합니다. 이때 사용하는 기술이 바로 GAN(Generative Adversarial Network)입니다. 이 GAN은 특정 데이터를 학습하면 추후에 그 데이터 세트와 분포가 비슷한 출력물을 내놓는 인공지능 네트워크의 한 종류입니다. 예를 들어 볼까요 ? 만일 한국은행이 지폐를 계속 보여주며 네트워크에게 지폐의 생김새에 대한 분포를 학습시키면, 나중에 진짜같은 위조지폐를 만들어 낼 수 있는 것이지요. 따라서 이 립싱크는 입술의 대략적인 주요 포인트만 인공지능에게 알려주면 진짜 사람같은 입술 모양을 만들어줄 수 있도록 학습됩니다.
하지만 그럴싸한 입모양을 유추하고, 유추된 입모양으로부터 실제 사람과 같은 하관을 합성해내는 것은 매우 복잡하기 업무이기 때문에 네트워크는 쉽게 학습이 되지 않았습니다. 특히 이 복잡한 일을 모두 네트워크에 잘 배우라고 무책임하게 전가시키는 경우, 소리와 입의 모양이 맞지 않거나 싱크가 다른모습, 비현실적으로 얼굴이 합성된 모습들을 쉽게 관찰할 수 있습니다.
저자는 비교군으로 이전의 SOTA network인 LipGAN을 예로 들었습니다.[1] 간단하게 요약하면 다음과 같습니다.
[네트워크 메커니즘]
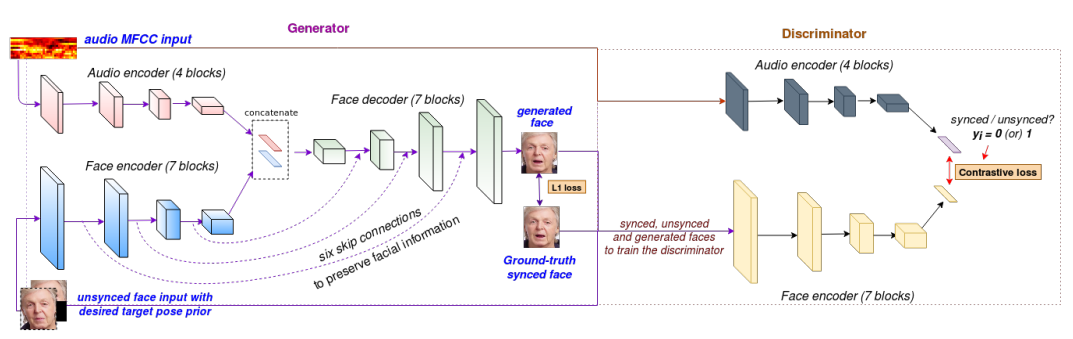
LipGAN을 개선하기 위해 저자는 Wav2Lip이라는 구조를 제안합니다.


4. 합성된 generated images와 ground truth images는 Visual Quality Discriminator를 통해 음성 데이터는 제외하고 오로지 vision image만을 들고와 사실적인 이미지인지 아닌지 평가합니다. LipGAN과 달리 contrastive loss가 아닌 Binary Cross Entropy loss를 사용하였습니다. 이들은 음성 싱크와는 무관하게 visual artifact를 제거하고 사실적인 얼굴 합성에만 집중할 수 있도록 돕는다. 수학에 집중할 수 있는 괴물 이과생을 양성하는 것이지요.
5. 합성된 이미지에 대하여 음성 데이터와 싱크가 잘 맞는지 판별하는 것은 전문가에게 맡깁니다. Pre-trained Lip-Sync Discriminator인 Expert를 들고와서 싱크 여부를 평가합니다. 평가를 받을때는 전문가에게 평가를 받아야지 나와 비슷한 수준의 사람에게 평가를 받아서는 발전할 수 없다는 것 입니다. 이 논문에서는 discriminator를 처음부터 학습시켜서 성능이 안좋을 때 loss를 부여 하면 맞았는데도 틀리다고, 혹은 틀렸는데도 맞았다고 판단할 위험이 있기때문에 싱크만을 전문적으로 판별할 수 있는 똑똑한 discriminator를 들고오자는 것이 요지입니다. 이는 합성된 이미지와 음성데이터에 대해 확실한 sync loss를 부여하도록 만든다고 주장합니다. 좀 더 정확하게는 cosine similarity loss를 할당하여 싱크가 잘 맞으면 1, 맞지 않으면 0으로 점수를 주는 것이지요.
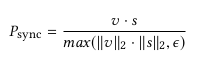
SyncNet은 영상의 합성 및 조작 여부를 판단하기 위해 등장한 네트워크입니다 [2]. 입모양과 audio의 MFCC 정보를 입력하게되면 싱크가 맞는 경우에는 각각의 embedding vector의 거리가 가깝게, 싱크가 맞지 않으면 embedding vector의 거리가 멀도록 만들어주는 네트워크입니다.
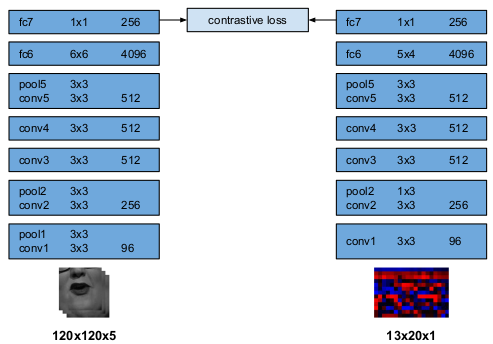
이때 frame과 음성데이터의 싱크가 잘 맞는지 여부를 판단하기 위해 **LSE-D(Lip-Sync Error Distance)**를 평가 항목으로 사용합니다.
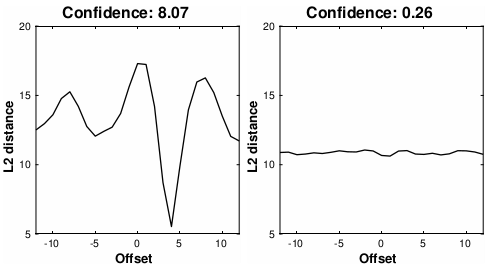
video frame과 audio의 시간에 대해 offset을 주며 embedding vector 사이의 distance를 비교하면 sync가 일치하는 순간(offset이 0인 부분)에 대해서는 LSE-D가 작게, offset이 커지면서 distance가 멀어지는 양상이 나타납니다. 하지만 오디오와 영상이 아예 관련이 없는 경우에는 오른쪽 그래프처럼 offset과 상관없이 distance가 꾸준히 멀게 나타나겠지요.
따라서 각 distance value의 변화에 따라서 싱크가 맞는 부분이 있는지 비디오와 오디오의 매칭 여부를 보기 위해 일종의 신뢰도 지표인 **LSE-C(Lip-Sync Error Confidence)**가 등장하였습니다. 이들은 distance의 median value와 minimum value의 차이로 계산합니다.

얼마나 현실감 있는 데이터를 형성했는지 평가할 때 많이 사용되는 metric입니다. generated data와 target data의 분포를 분석하여 활용합니다. 거리가 짧다는 것은 두 데이터의 분포가 비슷하다는 의미로 해석할 수 있습니다.
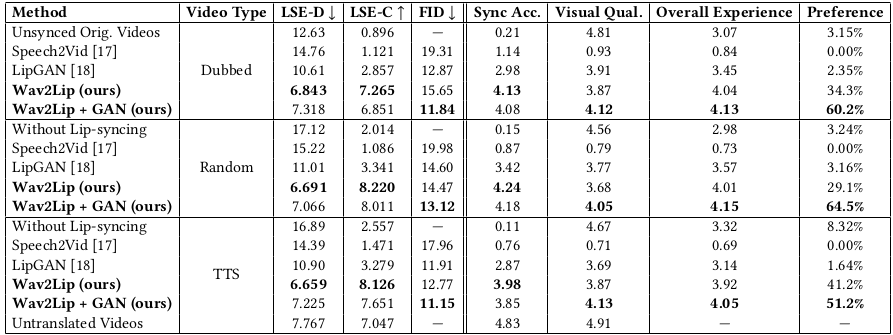
1. Temporal Window : 앞서 Baseline의 LipGAN과의 큰 차이점 중 하나로 Wav2Lip은 multi-frame을 입력으로 사용합니다. 실제로 frame 수를 늘려서 학습해 본 결과 temporal window가 증가함에 따라서 LSE-D와 LSE-C에서 모두 좋은 성과를 보여줌을 알 수 있었습니다.

2. Pre-trained Discriminator : Lip-Sync 여부만을 판단할 수 있도록 도와주는 pre-train network Expert를 이용한 결과 기존의 Speech2Vid [3], LipGAN보다 우수한 성능을 보여준다는 것을 LSE-D, LSE-C 평가 항목에서 확인할 수 있었습니다. Wav2Lip (ours) 참고

3. Pre-trained Discriminator : Lip-Sync 여부만을 판단할 수 있도록 도와주는 pre-train network Expert를 이용한 결과 기존의 Speech2Vid [3], LipGAN보다 우수한 성능을 보여준다는 것을 LSE-D, LSE-C 평가 항목에서 확인할 수 있었습니다. Wav2Lip (ours) 참고
기존에 비해 훨씬 더 정확한 립싱크 비디오를 합성해내기 위해 등장한 네트워크입니다. visual artifact를 제거하기 위한 discriminator의 이용에 국한되지 않고, 훨씬 더 뛰어난 synchronization을 위해 사전에 학습된 expert discriminator를 통해 성능을 한 층 더 끌어올렸다는 부분이 인상적이었습니다. 또한 성능 평가를 위한 다양한 metric과 dataset을 제공하였으며, 이에 멈추지 않고 실제 사람들로부터 사용자 경험을 통한 선호도 점수 평가를 통해 더 높은 객관성과 신뢰도를 증명하였습니다. 추후에는 자연스러운 발화 영상을 위해 gesture와 head pose 같은 motion representation이 추가될 것이며 이미 상당부분 연구가 되고 있습니다. 딥러닝을 통한 립싱크 합성 모델은 더욱 발전하여 인간에게 더 윤택한 서비스로 다가갈 것이라 기대됩니다.
[1] Towards Automatic Face-to-Face Translation
[2] Out of time: automated lip sync in the wild
[3] Adaptive subgradient methods for online learning and stochastic optimization
[4] Lip reading in the wild
[5] Deep Audio-Visual Speech Recognition
[6] LRS3-TED: a large-scale dataset for visual speech recognition
[7] U-Net: Convolutional Networks for Biomedical Image

㈜딥브레인AI 임직원은 고객에서 신뢰성(윤리) 높은 서비스를 제공하기 위하여 다음 사항을 적극적으로 실천할 것을 다짐한다.


