Lip sync technology, which generates the right movement of the lips for a given voice data, is one of the most popular field in deep learning. Let’s take a movie as an example. What if a foreign actor dubs according to the language of our country? Like an actor who lived in Korea for a long time, the meaning of speech will be expressed well, and the immersion will be much better. In addition it is not surprising that the news shows politicians from other countries speaking in Korean through deep learning technology. Therefore, natural and accurate lip sync technology is expected to bring a big leap forward to the future service and communication industry.

How will lip sync technology be implemented? It can be explained in two main steps. First, neural network learns to match the main coordinates of the lip shape syncing with sound.
Then, it learns to synthesize realistic lip based given set of mouth keypoints. The technology used at this step is the Generative Adversarial Network(GAN). This GAN is a type of neural network that releases outputs that has similar distribution with prior learned dataset which has certain features.
Let’s take an example. If the Bank of Korea teach neural network the shape or color distribution of the currency, it will be able to create realistic counterfeit note. Therefore, the neural network learns to make realistic human lip shapes if we teach the approximate main keypoints.
However, the network cannot easily learn the technique because the things that make realistic lip shape and synthesize the human lower jaw are very complicated tasks. In particular, if you irresponsibly pass on all of these complex homework to learn well to your network, it is easy to observe that the sound and lips don’t match with unrealistically synthesized faces.
The author cited LipGAN[1], the previous SOTA network, as a baseline. A brief summary is as follows.
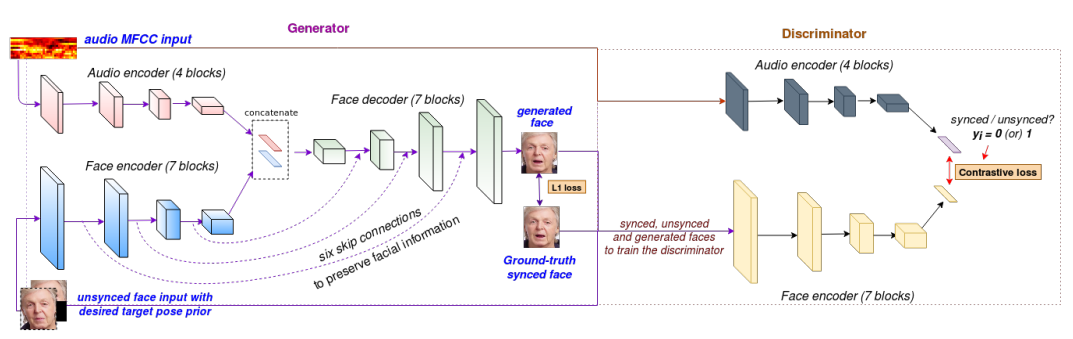
To improve LipGAN’s issues, the author proposes a structure called Wav2Lip.


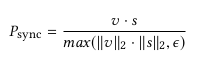
SyncNet is a network that has emerged to determine whether a video is fake or not[2]. When you input mouth shape of video and voice MFCC data, the network outputs the distance is close if the sync is right. If the sync is wrong, they output far distance between audio embedding vectors and video embedding vectors.
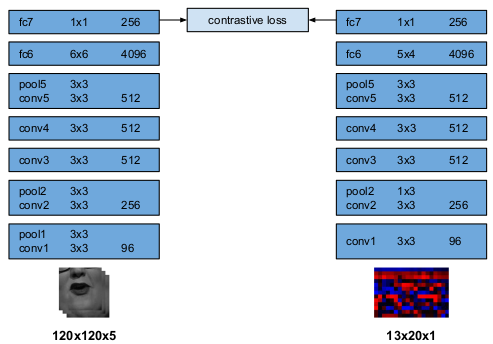
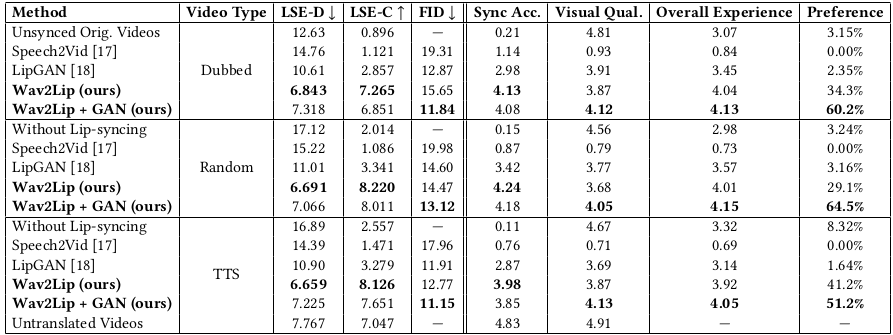
At this time, Lip-Sync Error Distance(LSE-D) is used as the evaluation item to determine whether the frame and voice data sync is right.
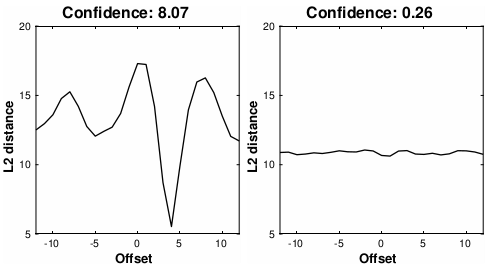
If you give temporal offset between video frame and audio, we can compare the distance between audio and video embedding vectors. For the moment when the sync matches(where the temporal offset is 0), the LSE-D is small, and the offset increases, causing the distance to move away. Therefore, Lip-Sync Error Confidence(LSE-C), a kind of reliability indicator, has emerged to see that video and sound have fit sync part according to the change in distance value. They calculate the difference between the median value and the minimum value of distance.

If you give temporal offset between video frame and audio, we can compare the distance between audio and video embedding vectors. For the moment when the sync matches(where the temporal offset is 0), the LSE-D is small, and the offset increases, causing the distance to move away. Therefore, Lip-Sync Error Confidence(LSE-C), a kind of reliability indicator, has emerged to see that video and sound have fit sync part according to the change in distance value. They calculate the difference between the median value and the minimum value of distance.
1. Temporal Window: One of the big differences from Baseline’s LipGAN is that Wav2Lip uses multi-frame as its input. In fact, as a result of learning by increasing the number of frames, it was found that both LSE-D and LSE-C showed good performances as the thermal window increased.

2. Pre-trained Discriminator : As a result of using the pre-train network Expert which helps to check only lip synchronization professionally, LSE-D and LSE-C evaluation items showed better performance than the existing Speech2Vid [3] and LipGAN models. refer to Wav2Lip (ours)

3. Visual Quality Discriminator : Unlike LipGAN, adding a discriminator that compares only vision images to determine real/fake showed a slight decrease in performance in LSE-D and LSE-C, but in terms of FID, visual image quality is much better. Therefore, you can express a much more realistic lip movement. It also received much higher preference and user experience scores. Refer to Wav2Lip + GAN(ours)
It is a network that can synthesize much more accurate lip sync videos than previous models. It was impressive that it was not limited to the use of discriminators to remove visual artifacts, but that it further boosted performance with extraneous discriminators learned in advance for much better synchronization. In addition, various metrics and datasets were provided for performance evaluation, and they proved higher objectivity and reliability through preference score through user experience. In near future, motion presentation such as gesture and head pose will be added, and much of the research is already being conducted. It is expected that the lip sync synthesis model through deep learning will develop further and approach humans as a richer service.
[1] Towards Automatic Face-to-Face Translation
[2] Out of time: automated lip sync in the wild
[3] Adaptive subgradient methods for online learning and stochastic optimization
[4] Lip reading in the wild
[5] Deep Audio-Visual Speech Recognition
[6] LRS3-TED: a large-scale dataset for visual speech recognition
[7] U-Net: Convolutional Networks for Biomedical Image





![[Deep.人. Article] DeepBrain AI’s Deep-Learning-based Video and Voice Synthesis Technology - DeepBrainAI](https://cdn.prod.website-files.com/63c4f0a436ce3226c46a7221/63c4f0a436ce329bc96a775a_rnd-deeplearning-01.jpeg)
